
In machine learning, the algorithm plays a significant role while training and building a successful model. According to the data and its behavior, a proper machine learning algorithm should be selected for a better ad accurate model. Many choices are available in machine learning to use algorithms with hyperparameter tuning, making the algorithm selection process complex and confusing.
This article will discuss the AdaBoost and Naive Bayes algorithms, their PROs and CONs, and the proper reason behind every advantage and disadvantage associated. This will help one to differentiate between AdaBoosta and Naive Bayes algorithms and will be able to make the picture of the algorithm precise in their mind.
Table of Content
- AdaBoost
- Naive Bayes
- Which is Better?
- Key Takeaways
- Conclusion
AdaBoost
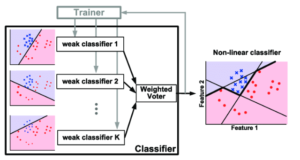
AdaBoost is a boosting algorithm known as the ensemble learning algorithm, which trains on the dataset with various techniques. The same machine learning algorithm is used as base models in boosting algorithms, and the data is split into parts for training. Once done, the information is fed to every base model sequentially, meaning that at a time, only one weak learning model will be trained on a particular set of datasets.
Now, as per the errors and mistakes of the first base model, the second base model will be trained so that it does not make the same mistake that the previous model does. This way, all base models are introduced, and the final model is obtained. The boosting model is also known as the sequential model, as every base model is trained in sequence, and at one time, only one model can be trained.
In the same way, for the AdaBoost algorithm, a base learner is defined before training the model, and the model calculates errors for every base model with mathematical formulations. The new weights are assigned to the next weak learner to avoid the same errors and mistakes that the previous model did.
PROs:
Robust to Overfitting
The AdaBoost algorithm is relatively robust to the overfitting problem in machine learning which is considered a very complex and common type of problem. As multiple algorithms are being trained for the final model, the model becomes robust to overfitting.
Accuracy
The algorithm gives very high accuracies on numerical and categorical types of data. An appropriate reason behind this is that the algorithms are training with learning to avoid the errors of the previous models, which means fewer errors and all the mistakes are eliminated at the end.
Easy
The maths behind the algorithm could feel complex and complicated. Still, the algorithm’s core intuition, a working mechanism, is straightforward to understand and one can easily describe abutting that in a very efficient manner with less practice.
CONs:
Outliers
The algorithm is affected by the outliers very frequently, meaning that the outliers affect the algorithm’s accuracy most; hence it should be treated before training on the noisy data.
Speed
As there are multiple algorithms involved in the training of the AdaBoost algorithm, the speed of training on the data and prediction is very slow for the algorithm.
Naive Bayes
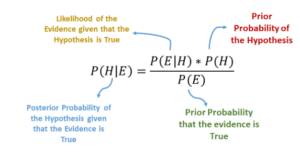
The Naive Bayes algorithm is a probabilistic algorithm that works on the principle of conditional probability and the bayesian theorem. Here, the conditional probability of every data point is calculated for every dependent that can happen, and the predictions are made depending upon the probabilities of data points.
The Naive Bayes algorithm is also known as the Naive because the algorithms assume that there is no multicollinearity in the dataset, meaning that there is correlation between the training dataset features and all of the features are independent of each other.
PROs:
Less Training Speed:
The algorithm trains very fast on the type of dataset as the algorithm only calculates the probabilities for every data point. Hence, the algorithm’s training is very fast compared to other algorithms.
Categorical Data Performance:
It is observed that the algorithm performs very well on the categorical data and gives an accurate classification model.
Easy
The algorithm’s mathematics and the working mechanism are easy to understand and implement.
CONs:
Multicollinearity:
The algorithm assumes that there is no multicollinearity present in the dataset, which makes it of no sense in the real world, as it is impossible every time to get a dataset that does not correlate its features.
Zero Frequency Error:
In a naive Bayes algorithm, if any data point or observation is not seen in the algorithm while training time, and if the data point is present in the testing set, then the algorithm will simply give it a zero probability to a particular point making it of zero frequency, which is quite unacceptable sometimes.
Which is Better?
We cannot say that one of the algorithms is always better than the other one, as both of the algorithms have their own PROs and CONs, which makes them perform well in some cases and poor in some cases. Although according to the dataset and its type, a proper algorithm can be selected. For example, if the dataset has multicollinearity, try to avoid using Naive Bayes, and if the data has outliers, try to avoid using AdaBoost.
Key Takeaways
- AdaBoost is a boosting algorithm that trains on multiple sets of datasets which multiple algorithms.
- AdaBoost assigns weights to the model and the data according to the eros and mistakes that the previous model makes.
- AdaBoost can be used to avoid overfitting in the data, but outliers make affect the accuracy of the algorithm.
- The naive Bayes algorithm assumes that there is no multicollinearity in the training data.
- The naive Bayes algorithm is a very fast algorithm that takes very less time to train and predict the data.
- Zero Frequency error is one of the major issue in the Naive Bayes algorithm, which assigns zero probability to unseen observations.
Conclusion
In this article, we discussed the AdaBoost and Naive Bayes algorithms with their core intuition, working mechanisms, advantages, and disadvantages. This will help me to differentiate between both algorithms and make the right choice of an algorithm according to the data and its patterns.